redis和mysql数据一致性
redis和mysql数据一致性
用缓存,就可能会涉及到缓存与数据库双存储双写,只要是双写,就一定会有数据一致性的问题,那么如何解决一致性问题?
canal介绍
官网资料:
概述
Canal是基于MySQL变更日志增量订阅和消费的组件
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
工作原理
MySQL主备复制原理
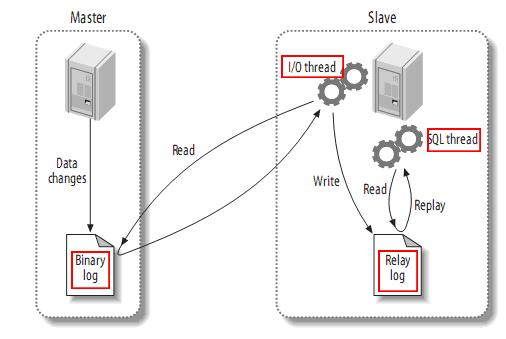
- 当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
- salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
- 同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
- slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
- salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
- 最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
canal工作原理

- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
使用案例
开启 MySQL的binlog写入功能
查看是否开启
SHOW VARIABLES LIKE 'log_bin';
如果没有开启,修改配置文件

新建'canal'账户,并设置任意远程ip可以访问,并赋权
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
canal服务端
下载:https://github.com/alibaba/canal/releases

修改配置文件:
canal.properties
重点关注:
- canal.port = 11111
- canal服务启动端口
- canal.destinations = example
- 实例名称,这里可以指定多个实例,多个实例用逗号隔开。一个实例即对应conf目录下的 包含instance.properties文件的文件夹,例如此处的example即表示默认的conf/example目录(下文将会着重介绍)
- canal.conf.dir = …/conf:配置文件目录
instance 实例配置
重点关注:
canal.instance.master.address=127.0.0.1:3306
- 配置数据库连接地址
canal.instance.master.journal.name=
- 配置mysql主库链接时起始的binlog文件,例如mysql-bin.000002,表示我跳过mysql-bin.000001的文件,直接从2开始。不指定表示从初始位置开始。在example实例中这里我们不指定
canal.instance.master.position=
- 配置mysql主库链接时起始的binlog偏移量。不指定表示从初始位置开始。在example实例中这里我们不指定
canal.instance.dbUsername=canal
- 数据库账号
canal.instance.dbPassword=canal
- 数据库密码
canal.instance.filter.regex
mysql 数据解析关注的表,Perl正则表达式
例如:mycanal schema下的一张表:mycanal.test1
改为默认即可:
canal.instance.filter.regex=.\\..
canal.instance.filter.black.regex
mysql数据解析表的黑名单,表达式规则见白名单的规则
在example实例中,我们只修改数据库连接信息,其他均按照默认配置来。
demo客户端
pom
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
CanalDemo
/**
* @Author LR
* @Date 2022/7/20 21:29
*/
public class CanalDemo {
public static void main(String args[]) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.83.133",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
//connector.subscribe(".*\\..*");
connector.subscribe("db2019.t_user");//指定数据库名和表名
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
测试:
运行程序:出现如下结果
empty count : 1
empty count : 2
empty count : 3
在数据库插入一条数据:出现如下结果
empty count : 50
empty count : 51
================> binlog[binlog.000035:1609] , name[db2019,t_user] , eventType : INSERT
id : 3 update=true
userName : 2 update=true
empty count : 1
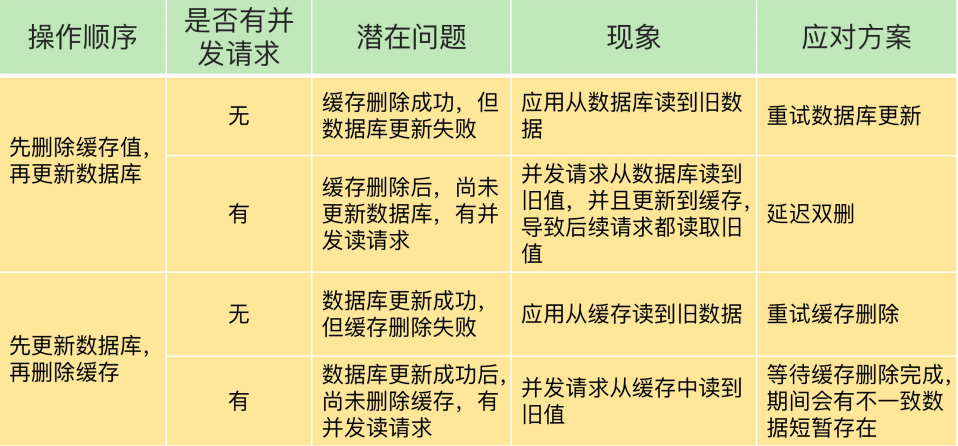
缓存双写一致性之更新策略探讨
双写一致性,你先动缓存redis还是数据库mysql哪一个?
这里主要讨论四种策略
先更新数据库,后更新缓存
举个例子比如在数据库中有一个值为 1 的值,此时我们有 10 个请求对其每次加一的操作,但是这期间并没有读操作进来,如果用了先更新数据库的办法,那么此时就会有十个请求对缓存进行更新,会有大量的冷数据产生,如果我们不更新缓存而是删除缓存,那么在有读请求来的时候先读数据库,再更新缓存,这样下来缓存只更新了一次。
数据库正常更新,缓存更新失败,用户读取的不是最新的数据,缓存数据库不一致.
先删除缓存,后更新数据库
问题:

**问题总结:**如果数据库更新失败,导致B线程请求再次访问缓存时,发现redis里面没数据,缓存缺失,再去读取mysql时,从数据库中读取到旧值
**解决方案:**其实最简单的解决办法就是延时双删的策略
public static void main(String[] args) throws Exception{
try {
Jedis jedis = RedisUtils.getJedis();
//1 线程A先成功删除redis缓存
jedis.del("key");
//2 线程A再更新mysql
orderDao.deleteBykey("key");
//暂停2秒 这两秒,就是等待B读取数据,并把旧值再写回redis的时间
TimeUnit.SECONDS.sleep(2);
//在删除一次缓存
jedis.del("key");
}catch (Exception e){
e.printStackTrace();
}
}
加上sleep的这段时间,就是为了让线程B能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程A再进行删除。所以,线程A sleep的时间,就需要大于线程B读取数据再写入缓存的时间。这样一来,其它线程读取数据时,会发现缓存缺失,所以会从数据库中读取最新值。因为这个方案会在第一次删除缓存值后,延迟一段时间再次进行删除,所以我们也把它叫做“延迟双删”。
这里的sleep时间怎么确定?
在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,自行评估自己的项目的读数据业务逻辑的耗时,以此为基础来进行估算。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上加百毫秒即可。
这种同步淘汰策略,吞吐量降低怎么办?
将第二次删除作为异步的,自己起一个线程,异步删除,这样写的请求就不用sleep了,加大吞吐量
当前演示的效果是mysql单机,如果mysql主从读写分离架构如何?
(1)请求A进行写操作,删除缓存 (2)请求A将数据写入数据库了, (3)请求B查询缓存发现,缓存没有值 (4)请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值 (5)请求B将旧值写入缓存 (6)数据库完成主从同步,从库变为新值 上述情形,就是数据不一致的原因。还是使用双删延时策略。 只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms
先更新数据库,后删除缓存
问题:

**问题总结:**假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读取到的是缓存旧值。
解决方案:
在我们业务逻辑的基础上,再加上canal,上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。
在时间t3时刻,如果更新缓存失败,将失败的数据暂存到消息队列中,重新从消息队列获取数据,重试删除。
先更新缓存,后更新数据库
这种场景不考虑,和第一种情况类似
总结
日常生产环境,会选择用方案2和方案3,但是具体该选择那个?
建议是:方案3,优先使用先更新数据库,再删除缓存的方案。理由如下:
1 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力,严重导致打满mysql。
2 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
但是方案3并非完美,实际开发中,需根据业务场景判断。