Spring AI 基础
Spring AI相关
目前大环境下,AI特别火热,作为一名JAVA开发者,也需要了解一下AI的相关知识。本文介绍SpringAI的一些相关知识。
Spring AI 简介
Spring AI 是 Spring 团队推出的一个用于简化 AI 应用开发的框架,支持多种 AI 服务商(如 OpenAI、Azure OpenAI、Hugging Face、Bedrock 等),并提供统一的 API 进行交互。官网:https://docs.spring.io/spring-ai/reference/
Spring AI 主要包括以下核心功能:
- 模型推理(Inference):支持文本、图像等多种 AI 任务。
- 聊天接口(Chat API):封装 LLM(大型语言模型)聊天能力。
- Embedding 支持:适用于向量数据库(如 Pinecone、Weaviate)。
- 代理模式(Agents):用于构建复杂的 AI 交互。
Spring AI 入门
Spring AI supports Spring Boot 3.2.x and 3.3.x
引入依赖,这里用的百度的千帆大模型,Spring Boot版本3.3.7 jdk版本 17
<!--集成 qianfan 大模型-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-qianfan-spring-boot-starter</artifactId>
<version>${spring-ai-version}</version>
</dependency>
配置文件,配置千帆大模型的api-key
server.port=8666
spring.ai.qianfan.api-key=key...
spring.ai.qianfan.secret-key=key...
使用千帆大模型
@RestController
@RequestMapping("/chat")
public class ChatController {
private final QianFanChatModel chatModel;
@Autowired
public ChatController(QianFanChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public String generate(@RequestParam(value = "message", defaultValue = "你好") String message) {
ChatClient chatClient = ChatClient.create(chatModel);
return chatClient.prompt()
// 提示词
.user(message)
.call()
.content();
}
}
测试返回
http://localhost:8666/chat/ai/generate

流式返回
@GetMapping(value = "/ai/generateStream",produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> generateStream(@RequestParam(value = "message", defaultValue = "你好") String message) {
ChatClient chatClient = ChatClient.create(chatModel);
return chatClient.prompt()
.user(message)
.stream()
.content();
}
嵌入模型(Embedding Model)
嵌入(Embedding) 的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像、视频的含义。
嵌入模型(EmbeddingModel)是嵌入过程中采用的模型。
使用案例
@RestController
public class EmbeddingController {
private final QianFanEmbeddingModel embeddingClient;
@Autowired
public EmbeddingController(QianFanEmbeddingModel embeddingClient) {
this.embeddingClient = embeddingClient;
}
@GetMapping("/ai/embedding")
public Map embed(@RequestParam(value = "message", defaultValue = "你好,我是kkrot") String message) {
EmbeddingResponse embeddingResponse = this.embeddingClient.embedForResponse(List.of(message));
return Map.of("embedding", embeddingResponse);
}
}
输出结果是 文子转换得到的向量数组
向量数据库
向量存储(VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,它特别适用于处理那些经过嵌入模型转化后的数据。在 VectorStore 中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore 返回与查询向量“相似”的向量。
Spring AI支持的向量数据库有很多,本案例使用 elasticsearch
安装elasticsearch
拉取镜像
docker pull elasticsearch:8.16.0
新建文件挂载用
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data/
mkdir -p /mydata/elasticsearch/plugins
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
启动并创建容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data/:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:8.16.0
引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store-spring-boot-starter</artifactId>
<version>${spring-ai-version}</version>
</dependency>
配置文件
spring.elasticsearch.uris=http://localhost:9200
# 是否初始化所需的 schema
spring.ai.vectorstore.elasticsearch.initialize-schema=true
# 用于存储向量的索引的名称
spring.ai.vectorstore.elasticsearch.index-name=ai_index
# 向量中的维数
spring.ai.vectorstore.elasticsearch.dimensions=1024
# 要使用的相似性函数
spring.ai.vectorstore.elasticsearch.similarity=cosine
# 计算嵌入时对文档进行批处理的策略。选项包括 TOKEN_COUNT 或 FIXED_SIZE
spring.ai.vectorstore.elasticsearch.batching-strategy=TOKEN_COUNT
代码
向向量数据库增加数据,并查询数据
@RestController
@RequestMapping("/es")
public class VectorEsController {
@Autowired
private VectorStore vectorStore;
@Autowired
private ElasticsearchVectorStore elasticsearchVectorStore;
@Autowired
private ChatModel chatModel;
/**
* 添加数据
**/
@RequestMapping("/add")
public void addVectorStore() {
List<Document> documents = List.of(
new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),
new Document("The World is Big and Salvation Lurks Around the Corner"),
new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));
elasticsearchVectorStore.add(documents);
}
/**
* 查询
**/
@RequestMapping("/query")
public List<Document> query(String msg){
return elasticsearchVectorStore.similaritySearch(msg);
}
}
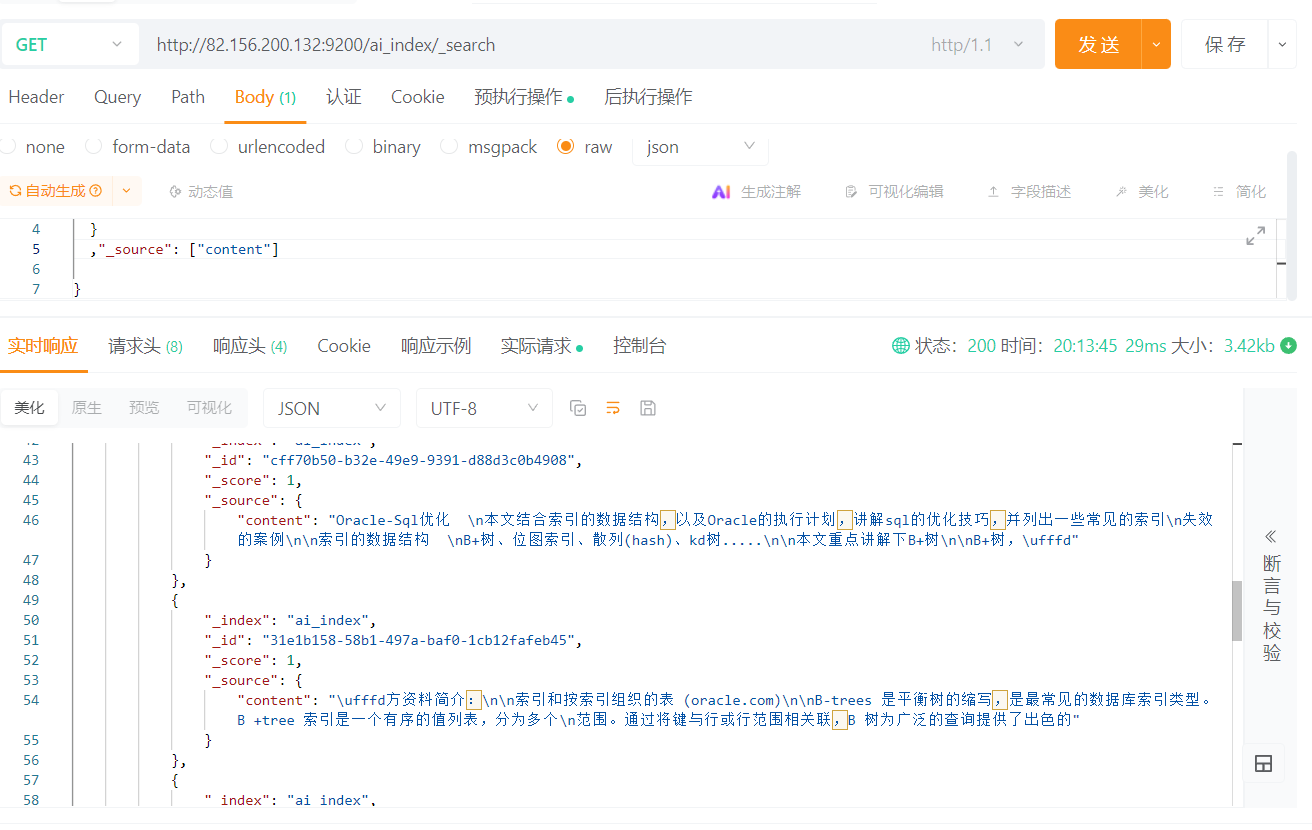
查询结果

ETL Pipeline
在 检索增强生成(RAG) 用例中,ETL(提取、转换、加载) 数据管道是数据处理的核心支柱。Spring AI 可以与 ETL 流程结合,从原始数据源提取数据,转换为结构化向量格式,并存入向量数据库,以便 AI 模型高效检索。
框架介绍
- DocumentReader:文档读取器,读取文档,比如PDF、Word、Excel等。如:
JsonReader(读取JSON),TextReader(读取文本),PagePdfDocumentReader(读取PDF),TikaDocumentReader(读取各种文件,大部分都可以支持.pdf,.xlsx,.docx,.pptx,.md,.json等)。上诉的这些reader都是DocumentReader的实现类。 - DocumentTransformer:文档转换器,处理文档。
TextSplitter(文档切割成小块),ContentFormatTransformer(将文档变成键值对),SummaryMetadataEnricher(使用大模型总结文档),KeywordMetadataEnricher(使用大模型提取文档关键词)。 - DocumentWriter: 文档写入器,将文档写入向量数据库或者本地文件。
VectorStore(向量数据库写入器),FileDocumentWriter(文件写入器)。
引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
读取文档
TikaDocumentReader比较全能大部分文件都可以读取,支持的文件格式可以参考官方文档
从本地读取文件
Resource resource = new FileSystemResource("D:\\test\\test.pdf");
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource);
转换文档
Document对象是ETL Pipeline的核心对象,它包含了文档的元数据和内容。
内容转换器:
TokenTextSplitter:可以把内容切割成更小的块方便RAG的时候提升响应速度节省Token。ContentFormatTransformer:可以把元数据的内容变成键值对字符串。
元数据转换器:
SummaryMetadataEnricher:使用大模型总结文档。会在元数据里面增加一个summary字段。KeywordMetadataEnricher:使用大模型提取文档关键词。可以在元数据里面增加一个keywords字段。
例如刚刚读取到的文件,转换为更小的块
List<Document> splitDocuments = new TokenTextSplitter(100, 350, 5, 15, true)
.apply(tikaDocumentReader.read());
存储文档
经过前面的步骤,我们得到了一个文档列表,然后就可以将其存储到向量数据库
这里以本站的一个oracle索引优化为用例,将内容保存到向量数据
@RequestMapping("/addVector")
public void addVectorStore2() {
Resource resource = new FileSystemResource("D:\\study\\test\\oracle.pdf");
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource);
// 将文本内容划分成更小的块
List<Document> splitDocuments = new TokenTextSplitter(100, 350, 5, 200, true)
.apply(tikaDocumentReader.read());
splitDocuments.forEach((e) -> {
System.out.println(Objects.requireNonNull(e.getText()).length() + "--" + e);
});
// 由于大模型限制单次添加的块数,这里我们每15个块添加一次
List<List<Document>> partition = Lists.partition(splitDocuments, 15);
for(List<Document> part:partition){
// 存入向量数据库,这个过程会自动调用embeddingModel,将文本变成向量再存入。
elasticsearchVectorStore.add(part);
}
}
上传结果